![]()
Pytorch is an open source deep learning library created in Python that enables tensor operations and automatic differentiation that are crucial to neural network training.
Pytorch is one of the leading frameworks and one of the fastest growing platforms in the deep learning research community mainly due to its dynamic computation graph where you can build, change and execute your graph as you go at run time, as opposed to a static graph where you define the graph statically before running it, this restricts the flexibility of the model during training. This excellent dynamic graph features of Pytorch speeds up data scientists to develop and debug AI projects.
The Pytorch package components as in the diagram shown below:
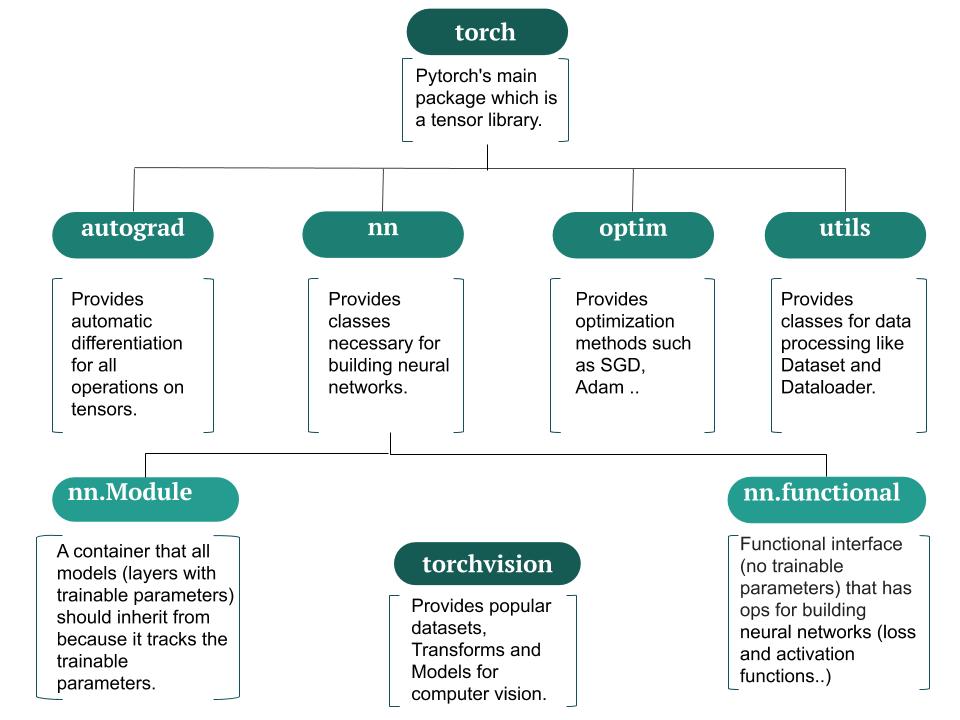
The key objects that make Pytorch different than other deep learning libraries are:
Tensors
Tensors are similar to NumPy’s ndarrays, except that tensors can run on GPUs or other hardware accelerators to speed up matrix multiplication resulting in faster training. PyTorch use tensors to encode the inputs and outputs of a model, as well as the model’s parameters. A nice tensors tutorials for this.
Autograd
After doing a forward pass through the network, you can call .backward() to backpropagate the gradient to the inputs using the chain rule, setting the requires_grad of a Tensor to True allows the gradient to backpropagate through its node in the computation graph, therefore you can access the gradient of this Tensor by calling the .grad method. The autograd package enables this automatic differentiation.
nn - neural network
Pytorch uses OOP to represent the dataset and model, the network class should inherit from nn.Module because it tracks the network’s parameters using .parameters and enables us to easily transfer the model between cpu and gpu using .to(device).
If you want to learn more about Pytorch, strongly recommend checking the Pytorch official tutorials.