
The Time-Series database has become hot recently. There have been many Time-Series database rises, the database trends over the past two year (Source from: DB-Engines) showing the popularity increasing significantly.
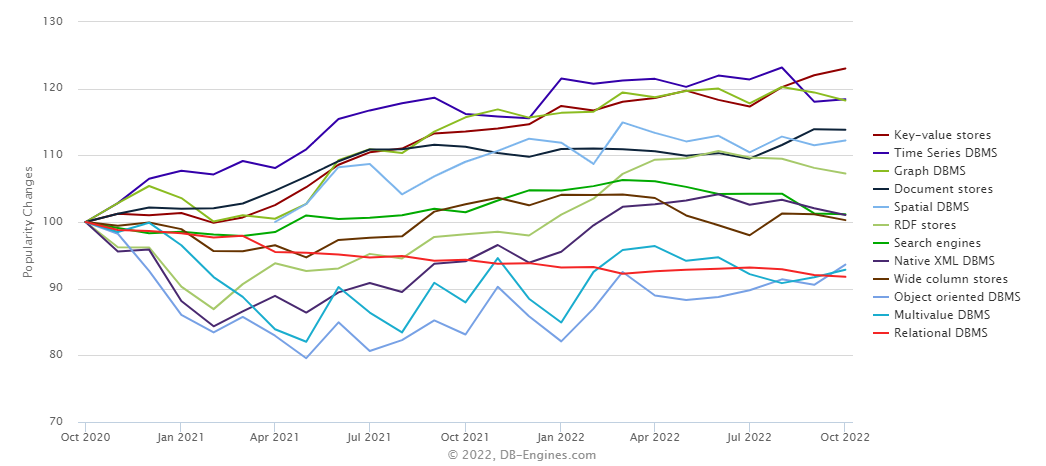
It is a good thing to have more choices, but it is also a bad thing to have too many choices. With past project experience, here are couple of keys considering factors when choosing the times-series database.
Scalability
In the Internet of Things (IoT) project, the scale of data is growing rapidly. A project can easily have a million device records to generate data streams. A typical approach to handling scalability is clustering, and this becomes the question or criterion when choosing the time-series database. To get a certain level of scalability, adding the proxy server between the application and the database layer is normal practice. It depends on the project sizing.
There is also an emerging new design for time-series databases, which store metadata in each virtual node instead of the central management node. This design can better solve the scalability requirement. The TDengine is one of the time-series database pioneers using this new design.
Streaming
Time-series data is stream data. In many projects, the requirements like, to quickly detect errors, to get operation insight faster etc., are common requirements in NFR (non-functional requirement). This stream processing can be time-driven, or data-driven, but either way, the streaming process capability is a fundamental requirement in a time-series database.
Data Subscription
Due to a heterogeneous system, the message queue is important in complex commercial projects. The incoming data is first written into a message queue in one application, then consumed by another system. The data may be temporarily stored in a queue system for some period. This type of message queue system has run in business environments for a long history.
It is not that smart to keep a message queue system in each project in this big data era. Particularly in the time-series related project, we can have a better approach to choosing the right database in architecture design.
As most time-series databases can ingest data efficiently, and they can apply a data retention policy to keep data storage shelf-life, if we choose a time-series database that can provide data subscription capability, then we can build a more agile and lightweight architecture for the project.
Conclusion
Each project has its own unique environment, the weighting factors for choosing a time-series database may be different. The above is shared from our project experience. Hope this sharing can have some benefits for your project. If readers have any related questions for us, welcome to drop a message to us.